Today I (re)learned that I should pay attention to the details of Linux kernel bugs associated with my favorite distribution. Especially if I’m working on CentOS 6/Red Hat Enterprise Linux (RHEL) 6 nodes running Transparent Huge Pages on Hadoop workloads. I was investigating some performance issues on our largest Hadoop cluster related to Datanode I/O and (re)ran across a discussion about this issue.
Huge Pages … how do they work?
In the Linux kernel, the standard size for a block of addressable memory is four kilobytes. This is called a page. Every system has a finite number of addressable pages, based on how much physical memory the system has installed. A page table is used to keep track of the location of each page in the system. This table can get gigantic.
For a single process that has hundreds of thousands of pages allocated for memory usage, you incur a measurable performance penalty as you iterate through that list. With Huge Pages, you can take a larger chunk of memory and give it a single address, allowing the page table to be smaller, but still addressing the same amount of physical memory. This provides a performance boost because both the kernel and the CPU have to keep track of fewer memory objects.
Huge Pages have some operational overhead. In the initial implementation, they needed to be pre-allocated at system boot time and you needed to make modifications to your code in order to explicitly take advantage of those pre-allocated Huge Pages.
But what about Transparent Huge Pages?
Transparent Huge Pages are an iteration on Huge Pages. Because of the complexity associated with with configuring Huge Pages and using them at run time, an effort was made to hide this complexity and have the kernel attempt to configure and use Huge Pages without any effort on the part of the developer or system administrator. This would give a “free” performance boost to applications utilizing large amounts of memory or large, contiguous chunks of memory.
Free Performance? Oh yeah!
Hold up there, buddy. TANSTAAFL. One of the downsides to using larger page sizes is that the kernel can only allocate the Huge Page in a contiguous chunk of memory. Over time, memory will get fragmented as Huge Pages are allocated and deallocated. The kernel will need to issue periodic memory compactions in order to get enough free memory to create Huge Pages or Transparent Huge Pages.
Unfortunately, when backporting the Transparent Huge Page support to RHEL6, Red Hat introduced some kind of bug. Of course, you can’t actually see the contents of it if you’re not a current Red Hat subscriber.
For reference, you can check out it out at:
2015-02-25 Followup: Â I ran across an additional bug that has a more thorough discussion regarding it: Â Red Hat Bug #879801 affecting Fedora. Â It is additionally discussed on LKML here and here. Â
Transparent Huge Pages are dead Jim
So, now that we know that Transparent Huge Pages are likely affecting us, how do we disable them? Red Hat describes it pretty succinctly.
There are two ways.
First, you can do this at boot time by placing transparent_hugepage=never in your /etc/grub.conf kernel command lines. This requires a reboot. If you use puppet, you can work with augeas and puppet to modify grub.conf
Alternatively, if you don’t want to reboot, you can do this at run time. The caveat is that you will need to create an init.d script to reset the state at each boot.
echo 'never' > /sys/kernel/mm/redhat_transparent_hugepage/enabled
Now, if you don’t want to completely disable Transparent Huge Pages, Cloudera Documentation for CDH4 suggests that you only need to disable the defragmentation of memory associated with Transparent Huge Pages. You can do that instead:
echo 'never' > /sys/kernel/mm/redhat_transparent_hugepage/defrag
Visualizing CPU Usage
So, now that we’ve disabled the Transparent Huge Pages, what can we expect? When I looked at this originally, I could not find a good performance description of the impact. So, we never implemented it.
Of course, two years later people are now able to find information. Oracle claims they see a 30% degradation in I/O performance when Transparent Huge Pages are enabled with Oracle DB workloads.
I was curious about how it would impact us. I turned Transparent Huge Pages off on my largest cluster which was showing very erratic system CPU usage.
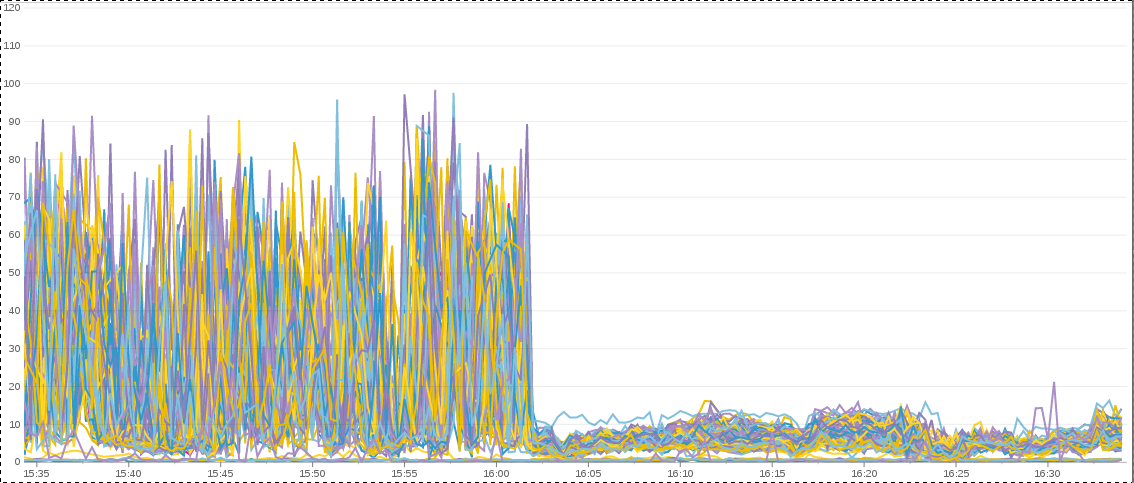
Dramatic System CPU drop disabling Transparent Huge Pages on Hadoop with CentOS6/RHEL6 Hadoop nodes
Holy. Crap. Now that is a dramatic drop. Note: this affects only the sys, not user, CPU utilization as far as I can tell. I’m still poking through the results to see if there are any other effects.
How did I miss this?
Well, I didn’t exactly miss it. When I originally came across this, the interwebs said this was primarily affecting the kernels in RHEL6.2 and RHEL6.3. We were beyond that. Additionally, CentOS Bug 5716 indicated that the issue had been resolved in CentOS6.4 (and thus, resolved by RHEL6.4). So I blew it off as being unnecessary to attempt to resolve. The bulk of our cluster is running 6.5 with a smattering of 6.4 peppered on older systems. Doing a new set of Google searches today, I came across a CentOS mailing list thread about transparent hugepage problems in 6.4 and 6.5. Go figure.
Looks like turning it off confirmed the issue, as evident in our performance graph above.
Live and learn. And now that we’re aware of it, we’ve begun looking at other places in our environment where we might be running into this issue. You probably should too.
References on Transparent Huge Pages on Hadoop
Now, I’m not the first to encounter this issue. If you’d like to learn more about it, here’s a few things that I came across in my work today.
- Structured Data: Linux 6 Transparent Huge Pages and Hadoop Workloads
- Linux Kernel Documentation – Transparent Huge Pages
- Linux Kernel Documentation: Huge Pages
- Red Hat Documentation: RHEL6 Performance Tuning Guide – Memory
- Google Translation: Meituan.com Tech team discusses Hadoop and Transparent Huge Pages
You must be logged in to post a comment.